Resolvendo problemas de Rate Limiter com Token Bucket e Semáforos
Como utilizar estratégias de rate limit para controlar o consumo de mensagens em arquiteturas distribuídas.
Para quem trabalha com arquiteturas distribuídas e comunicações assíncronas, esse cenário é bem comum:
Preciso controlar quantas mensagens devem ser processadas ao mesmo tempo pelos consumidores, para evitar o uso excessivo de recursos ou para seguir alguma regra de negócio específica.
Para resolver esse tipo de problema, temos algumas estratégias interessantes que podemos utilizar. É exatamente isso que quero trazer neste artigo, além da aplicação de exemplo que criei para validar cada um dos cenários:
O problema
Inspirado no universo de My Hero Academia, onde super-heróis recebem solicitações de serviço através de uma fila SQS, precisamos de controle, coordenação e limites para não causar problemas de excesso de requisições.
Cenário:
- Centenas de solicitações de heróis chegam simultaneamente
- Vários “escritórios de heróis” (containers) processam mensagens em paralelo
- Cada solicitação exige processamento confiável (nenhuma pode ser perdida)
- O sistema não pode sobrecarregar recursos críticos
Vamos agora explorar algumas estratégias para resolver esse problema…
🏗️Estratégia 1: Controle na aplicação (local)
Esta é a abordagem mais simples, onde o controle é feito dentro da própria aplicação/agência, limitando o que cada container individual pode fazer.
Como funciona (controle local)
Configuramos o listener do SQS para processar um número fixo de mensagens por vez. No Spring Cloud AWS, usamos as propriedades maxConcurrentMessages e maxMessagesPerPoll. Cada escritório de super-heróis faz seu próprio controle. No exemplo abaixo, são 3 solicitações por vez:
@SqsListener(
value = ["event-hero-orders-queue"],
maxConcurrentMessages = "3",
maxMessagesPerPoll = "3"
)
fun consumeMessage(message: Message<HeroOrderRequest>, acknowledgement: Acknowledgement) {
try {
orderService.processOrder(message.payload)
acknowledgement.acknowledge() // Confirmação manual
} catch (e: Exception) {
// Se falhar, volta para a fila automaticamente (validar maxReceiveCount)
}
}
Em cenários de rate limit ou backpressure intencional (Token Bucket ou Semáforo), a mensagem pode retornar várias vezes para a fila sem representar erro. Caso a fila tenha DLQ configurada, é necessário ajustar o maxReceiveCount para evitar que mensagens válidas sejam enviadas indevidamente para a DLQ apenas por falta momentânea de capacidade.
Vantagem
- ✔ Simples de implementar
- ✔ Não depende de componentes externos
Desvantagem
- ❌ Não escala bem
- ❌ Não existe uma visão global do limite
Se você tiver 10 containers com limite de 3 mensagens, terá 30 mensagens sendo processadas simultaneamente, independentemente da capacidade real do sistema.
Cenário não recomendado (controle local)
- ❌ Quando o número de containers escala dinamicamente
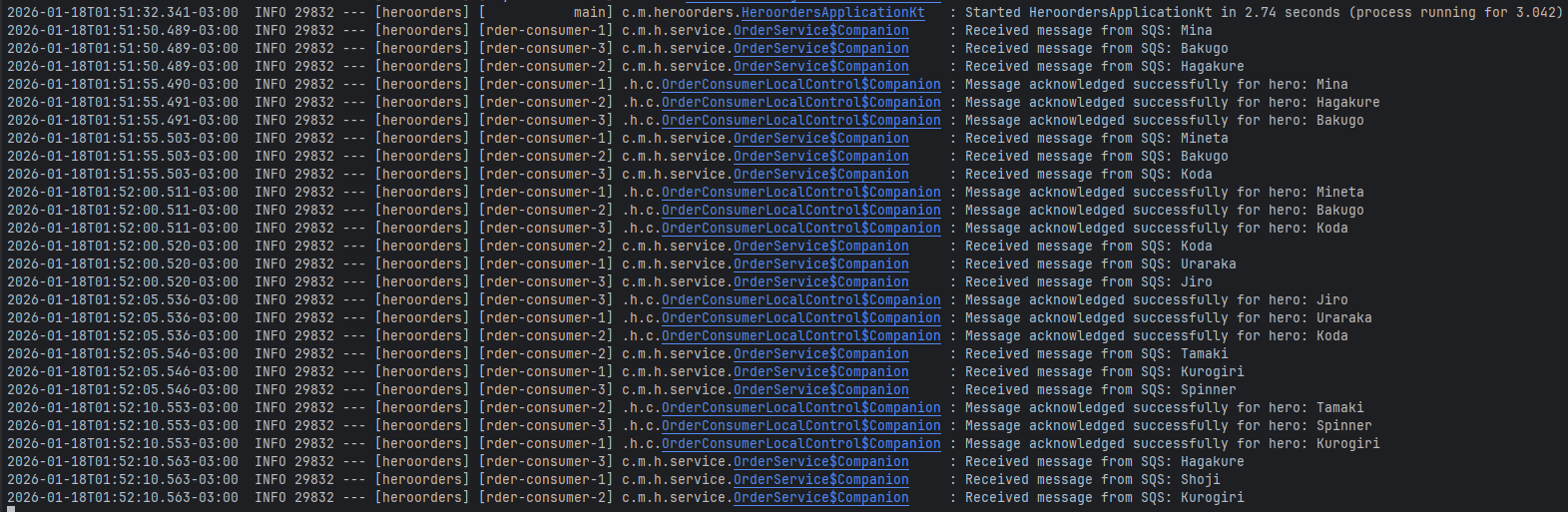
Execução (controle local)
Exemplo de itens sendo processados, de 3 em 3, com cada solicitação durante 5 segundos:
./mvnw spring-boot:run -Dspring.profiles.active=local-control
Agora podemos entrar um pouco em estratégias que funcionam melhor em cenários distribuídos:
🚥 Estratégia 2: Semáforos Distribuídos (Redis)
Quando precisamos garantir que, independente do número de escritórios de heróis (containers), apenas um certo número de solicitações sejam processadas simultaneamente no cluster todo, podemos usar um Semáforo Distribuído.
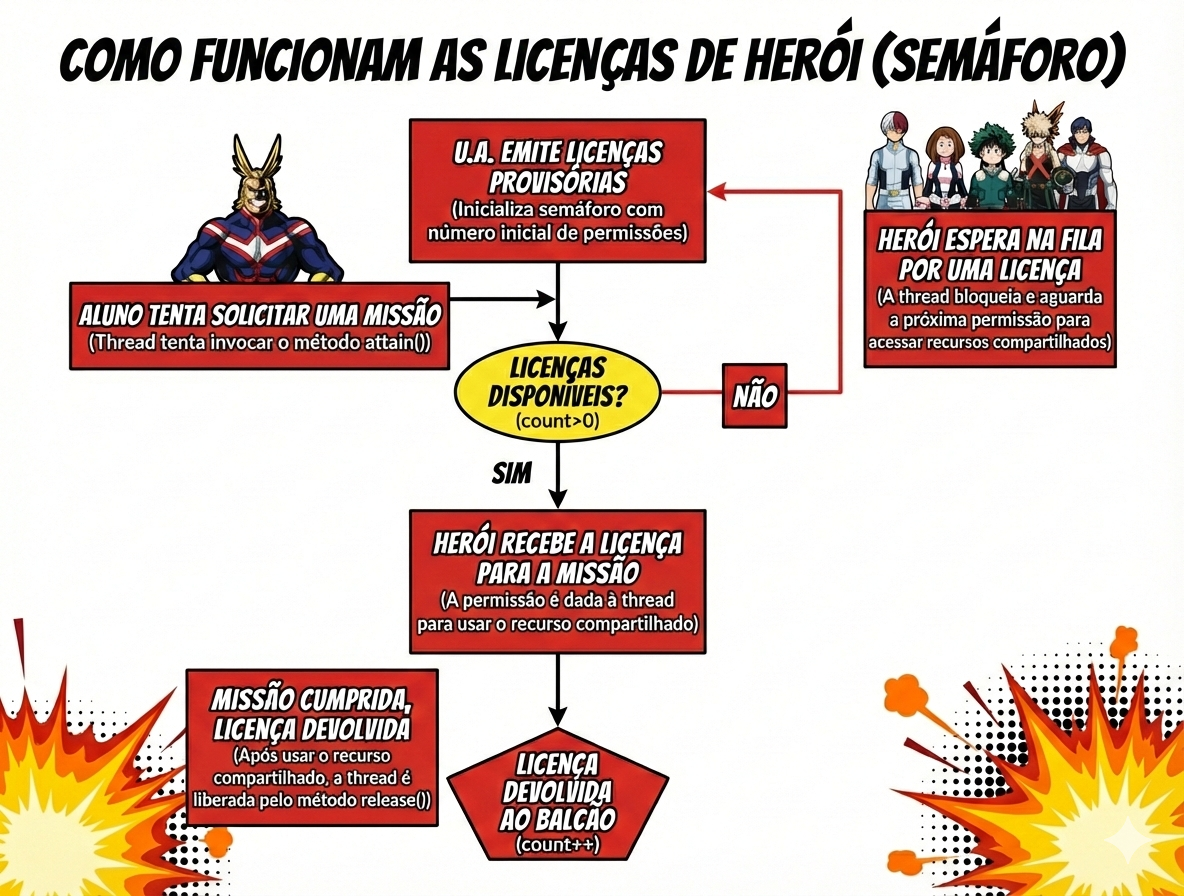
O Conceito
Definimos o Redis como uma fonte da verdade. Antes de processar a mensagem, o consumidor tenta adquirir um “permissão” (permit).
- O consumidor busca a mensagem no SQS.
- Tenta adquirir o permit no Redis.
- Conseguiu? Processa e, ao final, libera o permit.
- Não conseguiu? A mensagem não é confirmada (no-ACK) e volta para a fila para ser tentada novamente por outro (ou pelo mesmo) container.
@SqsListener(
value = ["event-hero-orders-queue"],
acknowledgementMode = "MANUAL",
id = "distributed-semaphores-order-consumer"
)
fun consumeMessage(message: Message<HeroOrderRequest>, acknowledgement: Acknowledgement) {
var permitId: String? = null
try {
// Tenta adquirir uma permissão do semáforo distribuído
permitId = distributedSemaphore.tryAcquire(message.payload.heroId)
if (permitId == null) {
// Não foi possível adquirir permissão, rejeita a mensagem para ser retentada depois
log.warn("Could not acquire semaphore permit for order: ${message.payload.heroName}. Message will NOT be acknowledged (returning to queue).")
// NÃO faz o acknowledge - a mensagem retornará à fila
return
}
// Processa o pedido com a permissão
orderService.processOrder(message.payload)
// Faz o acknowledge da mensagem apenas após o processamento bem-sucedido
acknowledgement.acknowledge()
log.info("Message acknowledged successfully for hero: ${message.payload.heroName}")
} catch (e: Exception) {
// Se o processamento falhar, NÃO faz acknowledge - a mensagem retornará à fila
log.error("Error processing message for hero: ${message.payload.heroName}. Message will NOT be acknowledged.", e)
// A mensagem retornará automaticamente à fila
} finally {
// Sempre libera a permissão se ela foi adquirida
permitId?.let {
distributedSemaphore.release(it)
}
}
}
Ponto Chave: O uso de TTL (Time-To-Live) nos permits do Redis garante que, se um container morrer, a permissão expire e não trave o sistema indefinidamente.
Cenário não recomendado (semáforo distribuído)
- ❌ Não usar para controle de taxa (ex: requisições por minuto)
- ❌ Não usar sem TTL (risco real de deadlock distribuído)
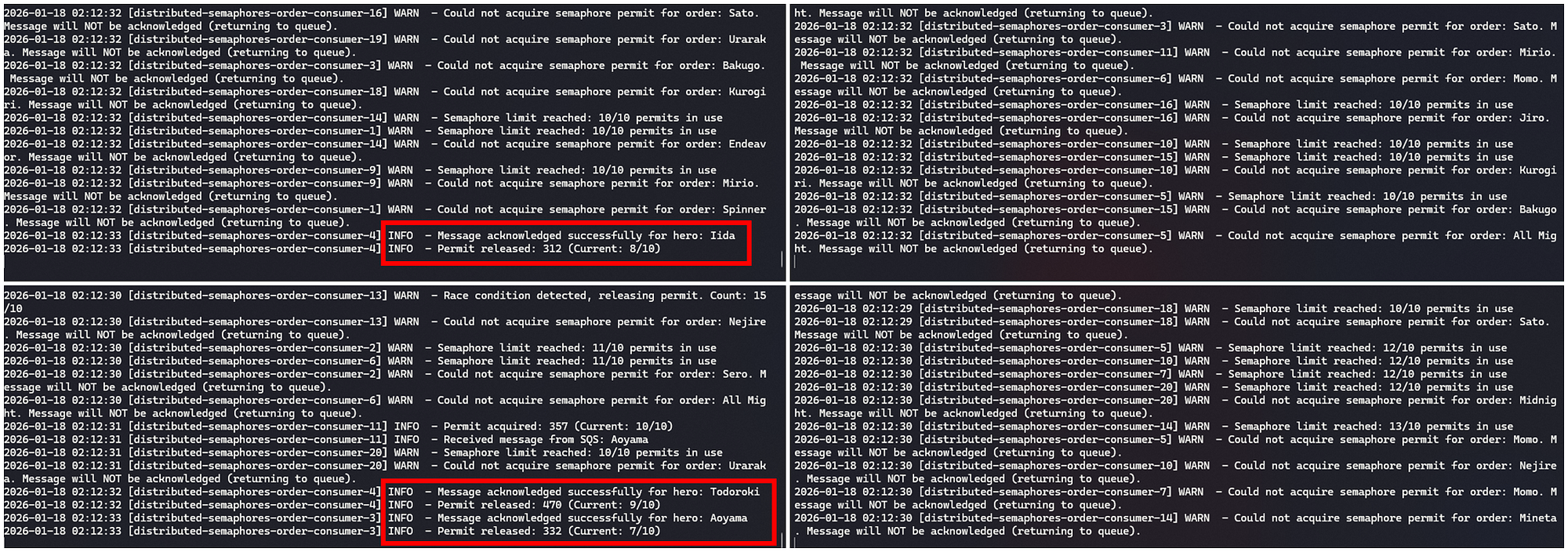
Execução (semáforo distribuído)
Exemplo de itens sendo processados conforme os recursos são liberados:
./mvnw spring-boot:run -Dspring.profiles.active=distributed-semaphores
🪣 Estratégia 3: Token Bucket Distribuído
Se o seu problema não é apenas a concorrência (quantos agora), mas sim a taxa de transferência (quantos por segundo), o algoritmo Token Bucket é a escolha ideal. Esse é o que mais vejo ser implementado no dia a dia!
Como funciona (token bucket)
Imagine um balde que se enche de “tokens” a uma taxa constante (ex: 2 tokens por segundo). Para processar uma mensagem, o consumidor precisa retirar um token do balde, para um novo serviço ser processado é necessário que os heróis estejam disponíveis para isso.
- Burst: Se o balde estiver cheio (ex: 10 tokens), o sistema pode processar 10 mensagens.
- Refill: Após o pico, ele volta a processar apenas na velocidade em que os tokens são repostos (2/s).
fun tryConsume(tokensNeeded: Int = 1): Boolean {
refillTokens() // Reabastece tokens baseado no tempo
val currentTokens = getCurrentTokens()
if (currentTokens >= tokensNeeded) {
// Consome o token atomicamente
redisTemplate.opsForValue().decrement(TOKEN_BUCKET_KEY, tokensNeeded.toLong())
return true
}
return false
}
Com isso o consumidor segue o seguinte formato:
@SqsListener(
value = ["event-hero-orders-queue"],
acknowledgementMode = "MANUAL",
id = "distributed-token-bucket-order-consumer"
)
fun consumeMessage(message: Message<HeroOrderRequest>, acknowledgement: Acknowledgement) {
try {
// Tenta consumir um token do bucket
if (!tokenBucket.tryConsume()) {
// Nenhum token disponível, rejeita a mensagem para ser retentada depois
log.warn("No token available for order: ${message.payload.heroName}. Message will NOT be acknowledged (returning to queue).")
// NÃO faz o acknowledge - a mensagem retornará à fila
return
}
// Processa o pedido se o token foi consumido
orderService.processOrder(message.payload)
// Faz o acknowledge a mensagem apenas após o processamento bem-sucedido
acknowledgement.acknowledge()
log.info("Message acknowledged successfully for hero: ${message.payload.heroName}")
} catch (e: Exception) {
// Se o processamento falhar, NÃO faz acknowledge - a mensagem retornará à fila
log.error("Error processing message for hero: ${message.payload.heroName}. Message will NOT be acknowledged.", e)
// A mensagem retornará automaticamente à fila
}
}
Cenário não recomendado (token bucket)
- ❌ Não usar quando o problema é concorrência simultânea
- ❌ Evitar usar sem que a operação seja atômica (como no exemplo acima).
Execução (token bucket)
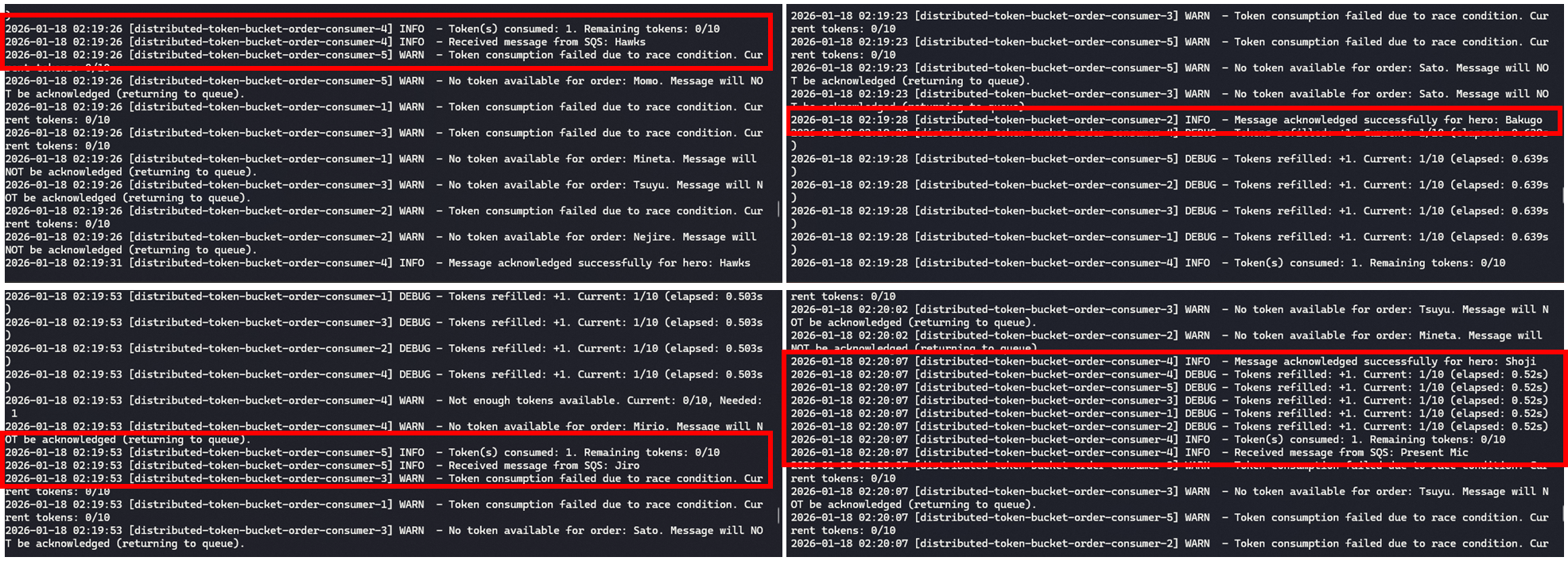
Processamentos sendo feitos com o uso de token bucket, muitas transações retornam para fila aguardando a liberação de mais fichas no balde.
🪣 Estratégia 4: Token Bucket Distribuído com Bucket4J
As implementações acima foram feitas de forma manual, vamos explorar um pouco uma solução de mercado para isso. Uma das mais famosas é o Bucket4J, uma biblioteca Java para rate limit baseada no algoritmo de token-bucket. Mas antes quero falar um pouco dos motivos que resolvi trazer essa solução para esse artigo a “Atomicidade”:
Atomicidade
Atomicidade garante que a operação de verificar a quantidade de tokens disponível e consumi-los aconteça como uma única operação indivisível.
Ou tudo acontece, ou nada acontece.
Sem atomicidade, o sistema fica vulnerável a race conditions, como no exemplo abaixo:
- Dois consumidores leem simultaneamente que há 1 token disponível
- Ambos acreditam que podem processar a mensagem
- Ambos decrementam o contador
- O limite é violado e mais mensagens são processadas do que o permitido
Na primeira implementação de token bucket não tínhamos essa garantia, por serem múltiplos comandos do Redis, não uma única transação atômica. Isso significa que dois ou mais consumidores podem intercalar operações e violar o limite do balde. A lib do Bucket4j usa uma estratégia CAS (comparar e trocar) sobre um único estado de bucket serializado no Redis.
Configurando o bucket4j
Configuração do Bucket4J, preferi separar em uma classe de configuração nesse caso:
@Configuration
class BucketConfig(
@Value("\${spring.data.redis.host:localhost}") private val redisHost: String,
@Value("\${spring.data.redis.port:6379}") private val redisPort: Int,
@Value("\${spring.data.redis.password}") private val redisPassword: String
) {
@Bean
fun bucket4jRedisClient(): RedisClient {
val redisUri = if (redisPassword.isNotBlank()) {
"redis://$redisPassword@$redisHost:$redisPort"
} else {
"redis://$redisHost:$redisPort"
}
return RedisClient.create(redisUri)
}
@Bean
fun bucket4jRedisConnection(redisClient: RedisClient): StatefulRedisConnection<String, ByteArray> {
return redisClient.connect(RedisCodec.of(StringCodec.UTF8, ByteArrayCodec.INSTANCE))
}
@Bean
fun bucket4jProxyManager(connection: StatefulRedisConnection<String, ByteArray>): ProxyManager<String> {
return LettuceBasedProxyManager.builderFor(connection).build()
}
@Bean
fun bucket4jConfigurationConfig(): BucketConfiguration {
return BucketConfiguration.builder()
.addLimit { limit ->
limit.capacity(MAX_TOKENS)
.refillGreedy(REFILL_TOKENS, Duration.ofSeconds(REFILL_PERIOD_SECONDS))
}.build()
}
@Bean
fun bucket(proxyManager: ProxyManager<String>, bucketConfiguration: BucketConfiguration): Bucket {
val bucket = proxyManager.builder().build(BUCKET_KEY) { bucketConfiguration }
log.info("Bucket4j initialized with capacity: $MAX_TOKENS tokens, refill rate: $REFILL_TOKENS tokens per $REFILL_PERIOD_SECONDS second(s)")
return bucket
}
companion object {
val log: Logger = LoggerFactory.getLogger(this::class.java)
const val BUCKET_KEY = "hero:orders:bucket4j:token_bucket"
const val MAX_TOKENS = 10L // Capacidade máxima do bucket
const val REFILL_TOKENS = 2L // Tokens adicionados
const val REFILL_PERIOD_SECONDS = 1L // Período de reabastecimento (1 segundo)
}
}
Com isso o controle fica no service da aplicação, validando se existem tokens válidos para uso naquele momento.
@Service
class RedisDistributedTokenBucket4j(
private val bucket: Bucket
) {
/**
* Tenta consumir um token do bucket
* @param tokensNeeded número de tokens necessários (padrão 1)
* @return true se o(s) token(s) foi(ram) consumido(s), false caso contrário
*/
fun tryConsume(tokensNeeded: Long = 1): Boolean {
val consumed = bucket.tryConsume(tokensNeeded)
if (consumed) {
val availableTokens = bucket.availableTokens
log.info("Token(s) consumed: $tokensNeeded. Available tokens: $availableTokens/$MAX_TOKENS")
} else {
val availableTokens = bucket.availableTokens
log.warn("Not enough tokens available. Current: $availableTokens/$MAX_TOKENS, Needed: $tokensNeeded")
}
return consumed
}
companion object {
val log: Logger = LoggerFactory.getLogger(this::class.java)
}
}
Vantagem (token bucket com bucket4j)
- ✔ Não há race conditions, o CAS (Compare-And-Set) garante atomicidade
- ✔ Fácil de configurar, com uma API simples e intuitiva
- ✔ Testado em produção por milhares de empresas
Sempre é bom considerar “opções de mercado” com soluções já prontas, onde a “roda” não precisa ser reimplementada.
Execução (token bucket com bucket4j)
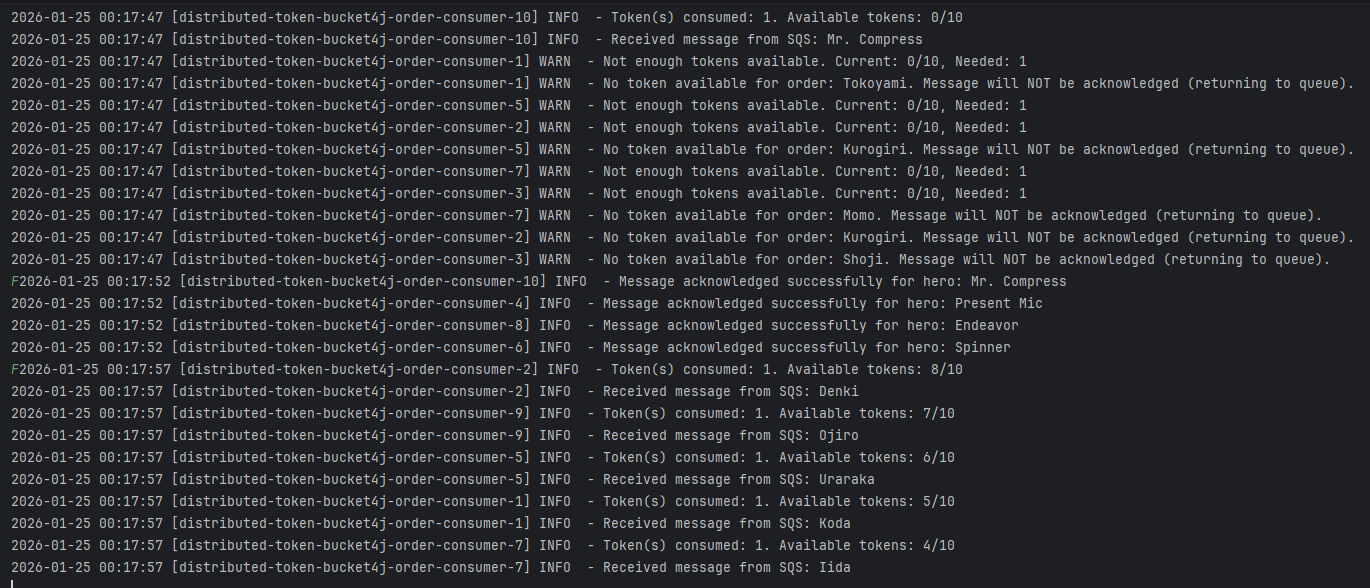
Exemplo de itens sendo processados utilizandos os tokens no bucket:
./mvnw spring-boot:run -Dspring.profiles.active=distributed-token-bucket4j
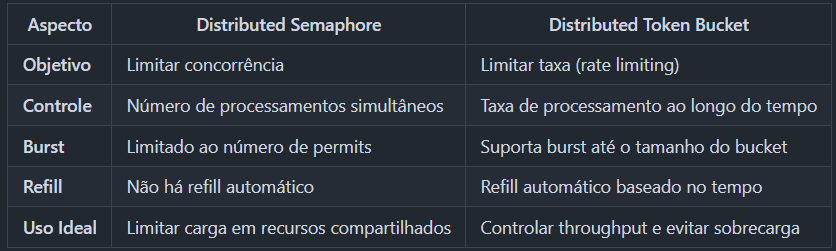
📊 Semáforo vs. Token Bucket
Colocando as duas opções lado a lado:
💡 Conclusão
Não existe “bala de prata” para rate limit.
- Se o controle é simples e o número de instâncias é fixo, um controle a nível de aplicação resolve!
- Se temos uma limitação relacionada a quantos itens simultâneos precisam ser processados, por exemplo, caso seu banco de dados não aguenta mais de 10 conexões simultâneas, use Semáforos.
- Se o controle precisa ser quantos processos são permitidos, como 100 itens por minuto, vá de Token Bucket.
- Mesmo que seja possível implementar soluções próprias, sempre busque utilizar soluções de mercado se possível.
O segredo está em entender o gargalo do seu sistema e escolher a estratégia que melhor protege seus recursos sem sacrificar a resiliência.
Caso tenha alguma crítica, sugestão ou dúvida fique à vontade para me enviar uma mensagem
Até a próxima!
Referências
- System Design — API Gateway | Matheus Fidelis (Token Bucket)
- Você Sabe o que é Token Bucket? Entenda de Forma Simples
- jjeanjacques10/rate-limit-hero-orders
Comentários